UPM for Enterprise delivers comprehensive high availability capabilities for mission-critical data services running on Kubernetes and OpenShift environments. Through its unified control plane, UPM ensures continuous operation of essential database and middleware services while maintaining data consistency and service reliability.
UPM for Enterprise High Availability Architecture
Our platform implements a multi-layered approach to high availability:
- Automated failover orchestration with configurable health checks and recovery procedures
- Cross-zone and cross-region deployment strategies for geographic redundancy
- Intelligent workload distribution through the Unit Operator for optimal resource utilization
- Real-time monitoring and proactive incident prevention
- Automated backup management with point-in-time recovery capabilities
The platform’s Unit Operator works in concert with native Kubernetes mechanisms to maintain service uptime while preserving data integrity during both planned maintenance and unexpected failures. This architecture enables enterprise customers to achieve their availability SLAs while significantly reducing operational overhead.
For mission-critical deployments, UPM extends beyond basic pod rescheduling to provide sophisticated orchestration of complex data service topologies, including primary-secondary replication, multi-node clusters, and distributed systems spanning multiple availability zones.
UPM for Enterprise delivers advanced high availability capabilities through its innovative Compose Operator, which orchestrates sophisticated replication topologies and failover mechanisms for enterprise data services running on Kubernetes and OpenShift environments.
The following sections detail the high availability design and architecture of UPM for Enterprise’s management plane through an examination of its three core components: UPM Platform, UPM Engine and Data Services running on it.
UPM Platform High Availability Architecture
UPM for Enterprise is developed based on the Spring Cloud framework, with its modular design shown in the following table:
| Items | Name | Description |
|---|---|---|
| 1 | upm-control-gateway | The Gateway API module is responsible for receiving external requests and routing them to the corresponding microservice module |
| 2 | upm-control-auth | The Auth module is responsible for user authentication and permission management |
| 3 | upm-control-resource | The Resource module provides management of system resources, such as projects, Kubernetes clusters, nodes, storage classes, software, etc. |
| 4 | upm-control-user | The User module is responsible for the management and operation of user information. |
| 5 | upm-control-operatorlog | The OperatorLog module records system operation logs for tracking system operations. |
| 6 | upm-control-mysql-ms | The MySQL service module provides complete operation and maintenance workflow control and management functions for MySQL databases. |
| 7 | upm-control-postgresql-ms | The Redis service module provides complete operation and maintenance workflow control and management functions for Redis cache. |
| 8 | upm-control-redis-ms | Redis-Cluster service module provides complete operation and maintenance workflow control and management functions for Redis cluster cache. |
| 9 | upm-control-redis-cluster-ms | Redis-Cluster service module provides complete operation and maintenance workflow control and management functions for Redis cluster cache. |
| 10 | upm-control-kafka-ms | The Kafka service module provides complete operation and maintenance workflow control and management functions for Kafka event flow. |
| 11 | upm-control-zookeeper-ms | The Zookeeper service module provides complete operation and maintenance workflow control and management functions for Zookeeper Service Discovery. |
| 12 | upm-control-elasticsearch-ms | The Elasticsearch service module provides complete operational workflow control and management capabilities for the Elasticsearch search engine. |
Note: Each module listed above is deployed as a Kubernetes Deployment, supporting multiple replicas to ensure high availability. Service discovery and failover (UPM Platform) are implemented using mature opensource frameworks running in cluster mode for enhanced reliability.
UPM Engine High Availability Architecture
UPM Engine is developed using the Operator pattern and ensures controller high availability through Leader Election mechanism. Here’s a detailed overview of our high-availability design:
Ensures continuous Operator availability with rapid recovery from any single-node failure Implements Leader Election to guarantee that only one replica processes resource events at any given time, preventing race conditions and conflicts Provides rapid failover capabilities to maintain stable Operator operations

The Operator is architected for maximum reliability in enterprise production environments. It employs a distributed deployment model with built-in redundancy, running as multiple replicas across your Kubernetes cluster. Our recommended configuration of three or more replicas ensures continuous operation even during maintenance windows or unexpected node failures. Intelligent workload placement is achieved through advanced pod anti-affinity rules, automatically distributing Operator instances across different nodes and availability zones. This architecture prevents single points of failure and maintains operational resilience.
Leader Election and Failover The Operator implements leader election using Kubernetes Lease objects to coordinate multiple replicas in distributed environments. This ensures that exactly one instance actively manages resources while maintaining automated failover capabilities.
Leadership Coordination The system employs a state management protocol to control replica behavior and leadership transitions. Primary and standby replicas maintain health checks and state synchronization, enabling seamless failover operations with minimal disruption.
High Availability Configuration
Key parameters can be configured to optimize the high availability behavior:
- Leadership lease duration: Controls the maximum time a leader can maintain control without renewal
- Health check intervals: Determines how quickly failures are detected
- Leadership renewal deadlines: Sets boundaries for lease renewal operations
Failover Process
The failover system operates through a defined sequence:
- Health Monitoring The system monitors leader health through Kubernetes Lease objects, with configurable monitoring intervals to match your environment’s requirements.
- Leadership Transition Upon leader unavailability detection, the system initiates a leadership transition process. Standby replicas coordinate through Kubernetes’ native concurrency controls to ensure exactly-once leadership acquisition.
- State Reconciliation The new leader performs these steps upon assuming leadership:
- Inventories all managed resources
- Verifies current state against desired configuration
- Executes necessary reconciliation actions
- Maintains consistency throughout the transition
Failover typically completes within seconds while maintaining strict consistency of managed resources.
Advanced Scheduling and High Availability Design
UPM implements sophisticated scheduling strategies for high availability when using local storage in Kubernetes. The system ensures primary and secondary nodes are distributed across different physical nodes to maximize fault tolerance.
Scheduling Architecture
The scheduling system leverages Kubernetes native mechanisms to control pod placement:
- Node Affinity rules guide pod placement to specific nodes based on operational requirements
- Pod Anti-Affinity policies prevent multiple pods from being scheduled on the same topology domain
Host Group Management
The system uses node labels (e.g., hostgroup=alpha, hostgroup=beta) to define host groups and topology awareness. This labeling scheme enables the scheduler to make informed decisions about pod distribution across different infrastructure layers.
High Availability Strategies
- Node-Level High Availability
- Uses Pod Anti-Affinity with kubernetes.io/hostname to distribute primary and secondary nodes across different hosts
- Provides protection against single-node failures
- Best suited for basic high availability requirements
- Host Group High Availability
- Implements Pod Anti-Affinity using hostgroup labels to ensure distribution across different host groups
- Offers enhanced protection against rack or zone-level failures
- Requires sufficient resource availability across host groups
Failure Detection and Recovery
The system maintains service availability through:
- Health Monitoring: Continuous health checks via liveness and readiness probes
- Automatic Rescheduling: Kubernetes-managed pod redistribution when nodes become unavailable
- Failover Management: Automated promotion of secondary nodes when primary nodes fail
The scheduling design prioritizes both availability and consistency, ensuring that services remain operational during infrastructure events while maintaining their required topology distribution.
Data Service High Availability Architecture
MySQL High Availability Management
Our Compose Operator extends beyond traditional Kubernetes operators by managing replication relationships without direct pod lifecycle control. This unique architecture enables:
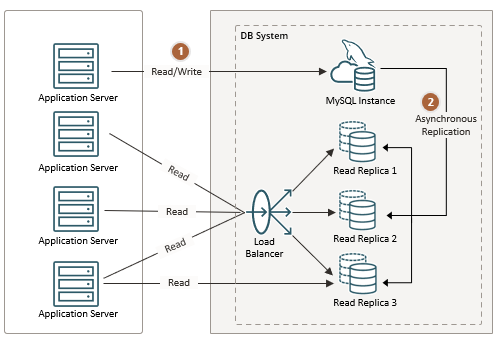
- Seamless integration of both in-cluster and external database instances
- Automated management of MySQL primary-secondary replication topologies
- Dynamic read-write splitting through intelligent pod labeling
- Automatic primary node election during failover scenarios
- Real-time monitoring and maintenance of replication health
Important: MySQL high availability architectures have evolved significantly over time, presenting various complexity challenges. UPM for Enterprise streamlines this complexity by implementing Semi-Synchronous Replication as the default configuration, deliberately avoiding additional proxy layers. This architectural choice maximizes operational simplicity while maintaining enterprise-grade availability requirements. Additionally, the platform offers extensible support for alternative MySQL high availability configurations, allowing enterprises to implement custom topologies based on their specific requirements.
PostgreSQL High Availability Management
The platform provides robust high availability solutions for PostgreSQL deployments:
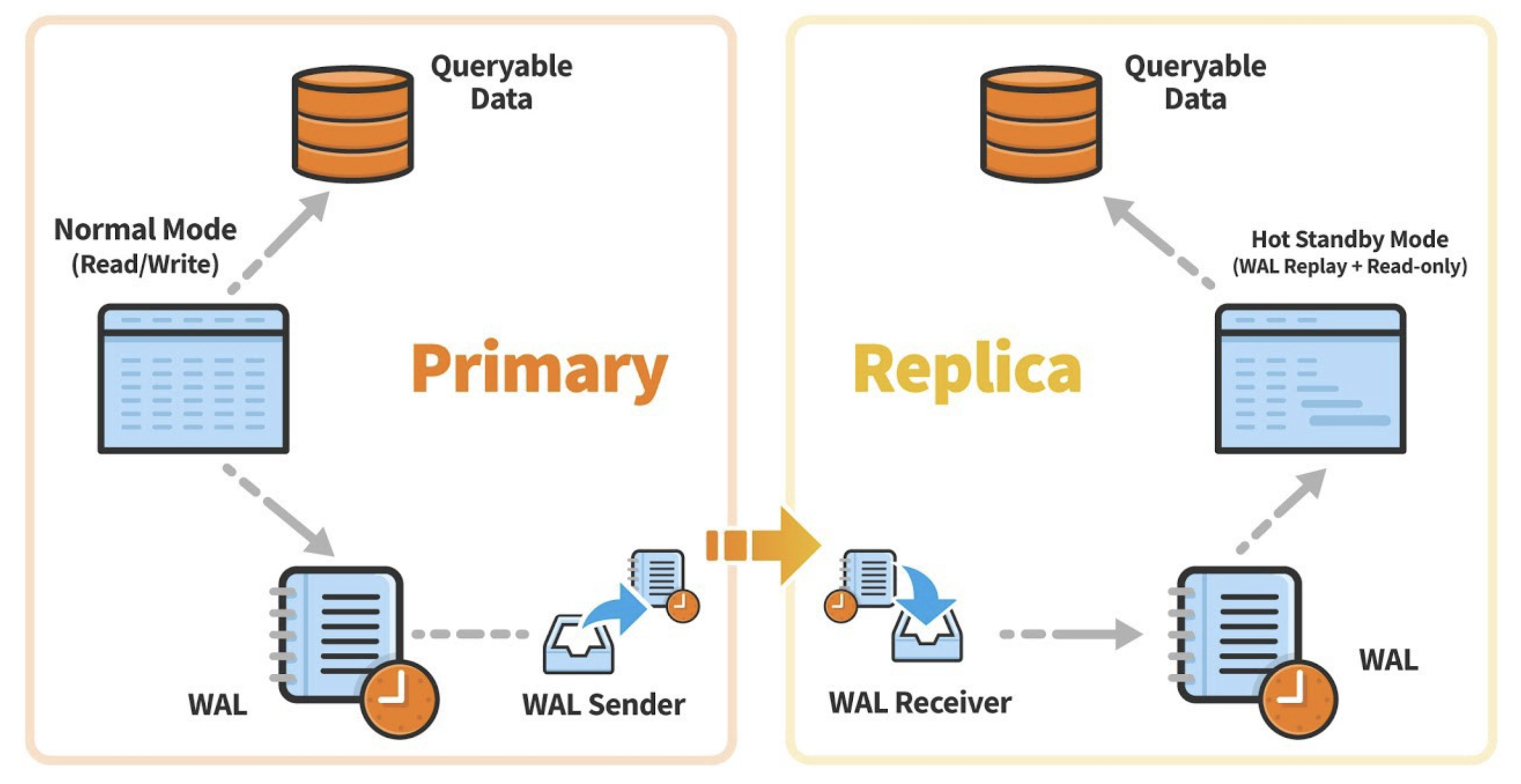
- Automated streaming replication configuration and maintenance
- Intelligent management of synchronous and asynchronous replication modes
- Advanced WAL (Write-Ahead Log) archiving and recovery orchestration
- Automated promotion of standby instances during failover events
- Comprehensive monitoring of replication lag and health metrics
Redis High Availability Solutions
The platform provides comprehensive high availability for Redis deployments through:
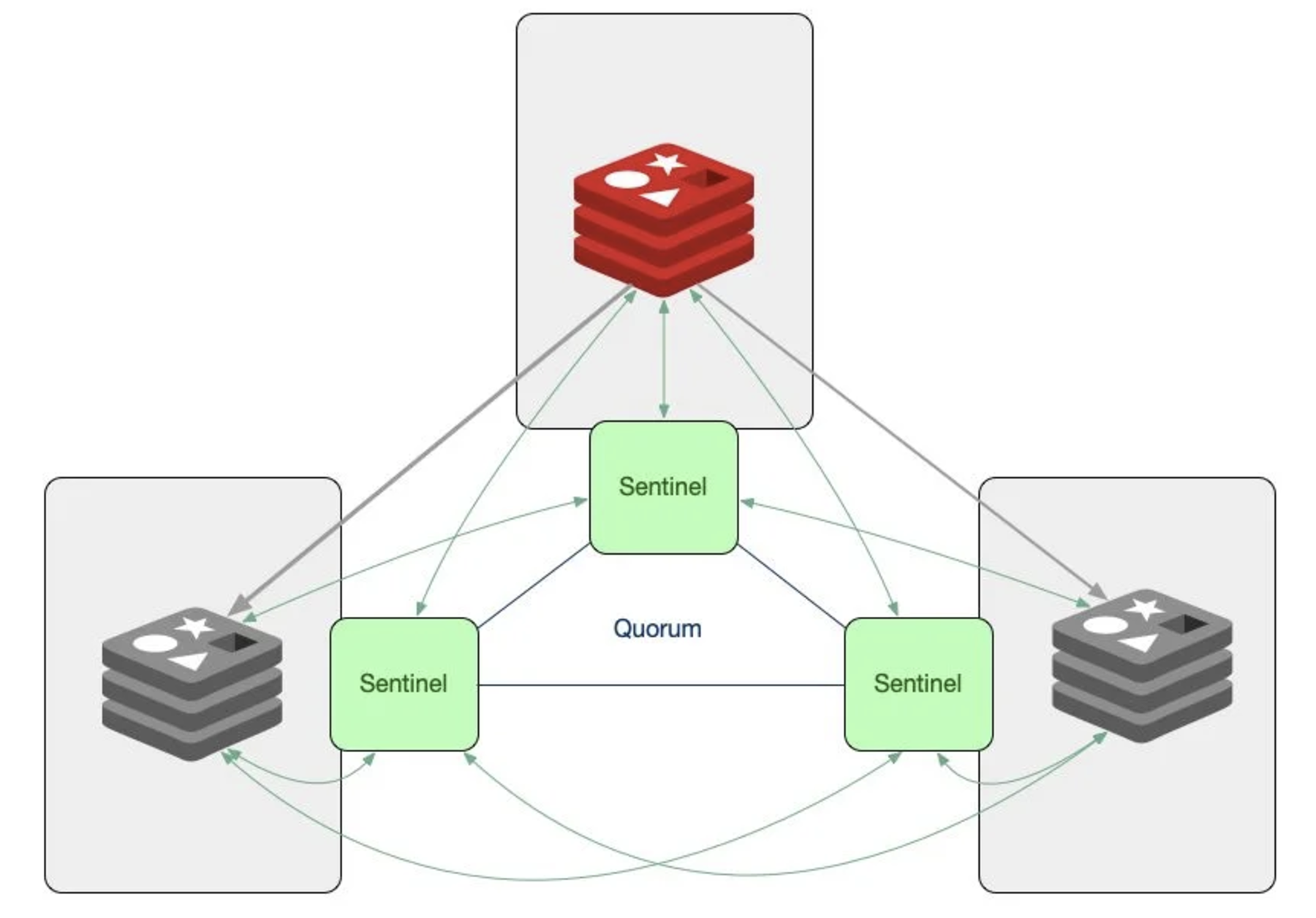
- Automated Redis primary-secondary replication management
- Native integration with Redis Sentinel architecture
- Intelligent Redis Cluster orchestration with automatic slot allocation
- Dynamic shard redistribution based on cluster load patterns
- Automated failover with minimal service interruption
Advanced Load Balancing and Failover
UPM’s ProxySQL integration delivers sophisticated traffic management capabilities:

- Real-time synchronization with MySQL and PostgreSQL replication topologies
- Automated maintenance of ProxySQL server groups
- Intelligent routing rules based on current database states
- Automated user synchronization with fine-grained filtering
- Seamless failover coordination across the database tier
Warning: While ProxySQL is a widely-used third-party proxy solution, it has documented limitations and potential stability issues when implemented with MySQL or PostgreSQL replication architectures. For production environments, we strongly recommend implementing the officially supported proxy solutions:
- For MySQL: MySQL Router as the first option
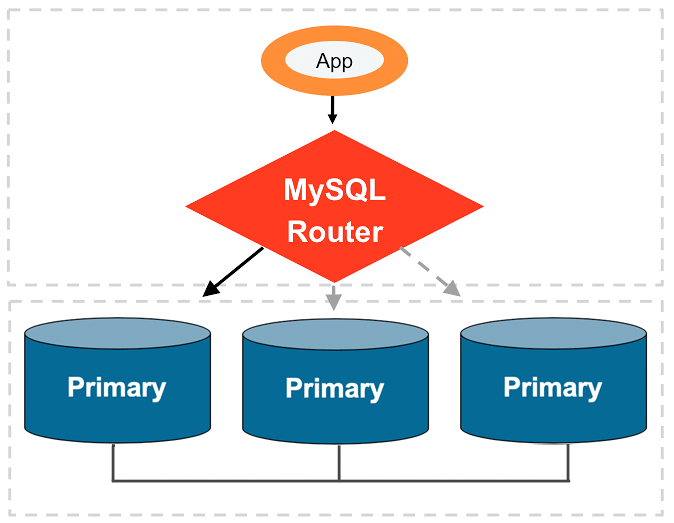
- For PostgreSQL: PostgreSQL native connection pooling or listed options from the PostgreSQL community
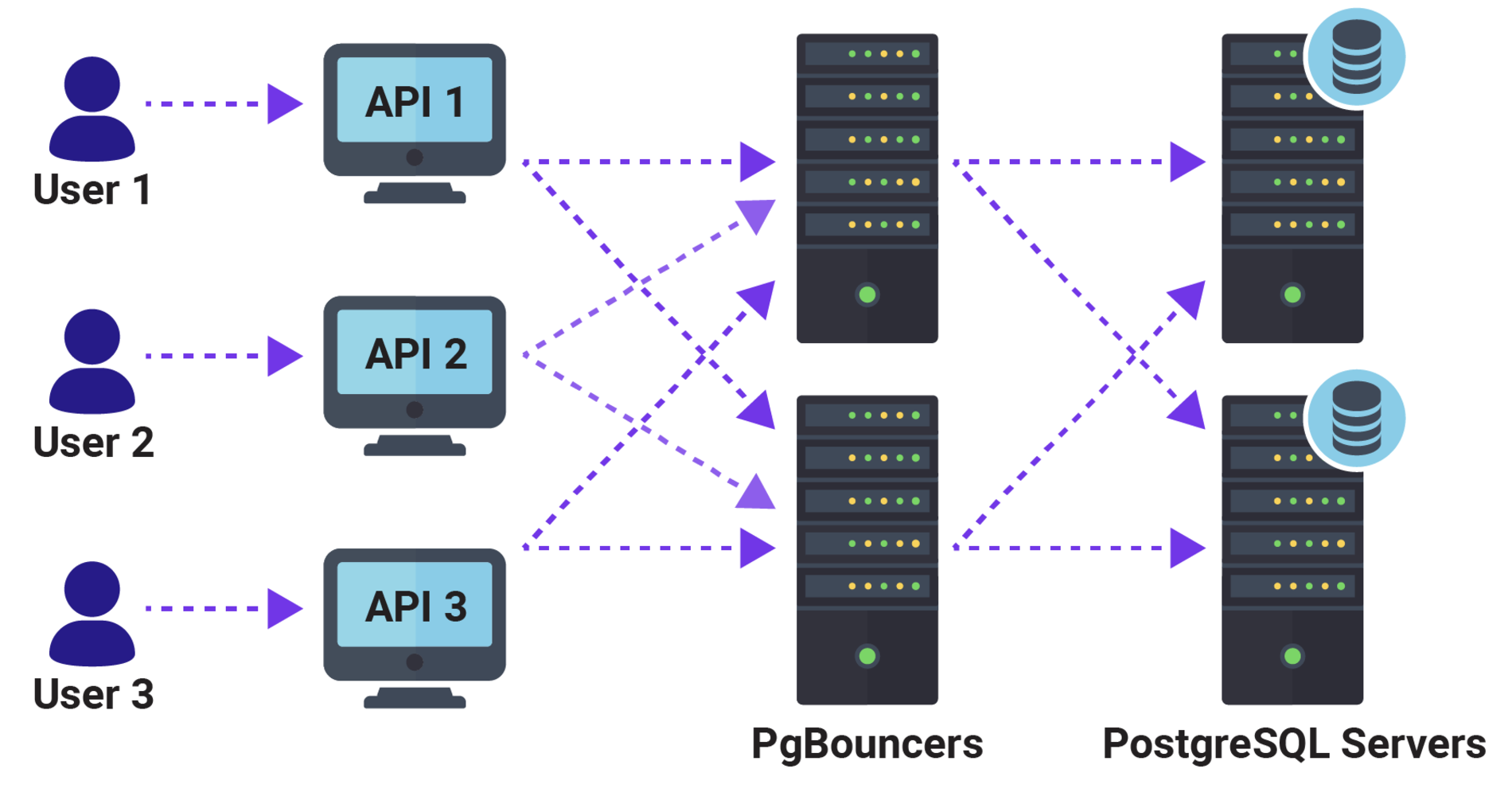
This recommendation aligns with enterprise best practices and helps ensure optimal performance, reliability, and supportability of your database infrastructure.
Enterprise-Grade Architecture
Our extensible operator framework is designed for enterprise requirements:
- Minimal operational overhead through automated topology management
- Consistent data reliability across distributed database instances
- Flexible customization options for specific business needs
- Comprehensive monitoring and alerting integration
- Zero-touch failover orchestration for business continuity